Why Padding?
- If we don't use padding, we end up shrinking the size of output. With padding, we can keep input and output as the same size.
- Without padding, the pixels near the edge will have fewer contribution than pixels in the middle of the picture. That said, without padding, we might throw information from edge.
Two Padding Schemes
Here, we have Input size(n), conv filter size(f), and output size(o):
Valid(in tensorflow:
"VALID"): without padding, the output size after padding isSame (in tensorflow:
"SAME"): with padding, the output size after padding is , where is the size of padding. note: when , then the output size = input size
By convention, size of filter is usually odd, one reason is that we can have a even padding p; another reason is that in computer vision literature, it's nice to have a pixel, you can call the central pixel so you can talk about the position of the filter.
Strided convolution
Instead of moving around one step each time,
input size:
filter size:
padding size:
stride size:
output size:

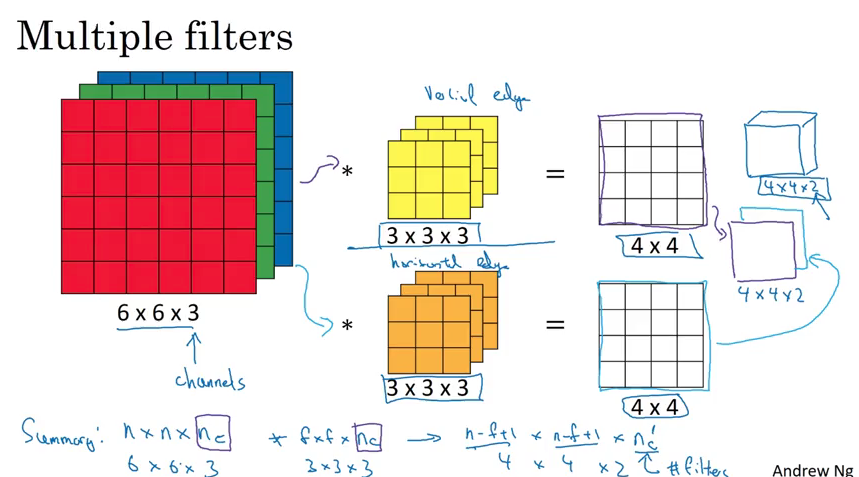
Convolutions over volume
If the image is (c is number of color channels), e.g., 6x6x3, then you convol with a filter(for example, it will detect vertical lines) to get a 2D output. If you want to detect horizontal lines, then you have another filter , then your output will be . Here, we stack the output together.
One Layer of Convolutional Network
s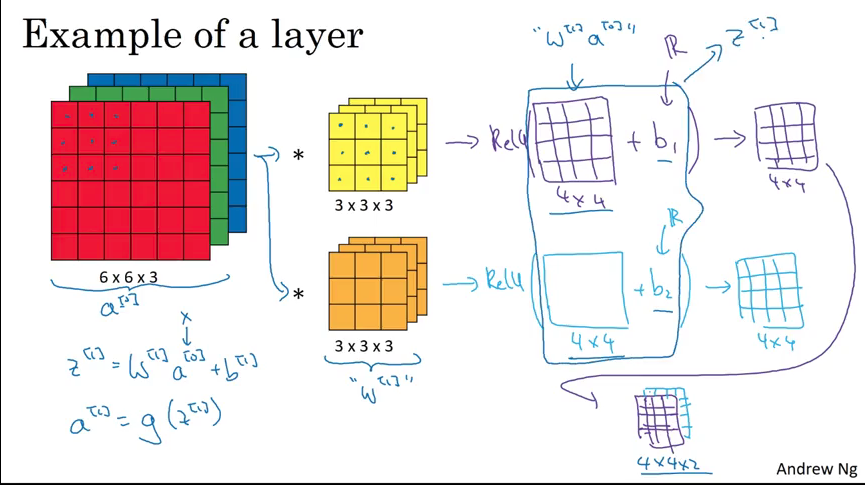

What's MaxPooling?
Divide the input into regions as the same size as maxpooling filter. So what the max operation does is so long as the feature is detected anywhere in one of these quadrants, it then remains preserved in the output of Max pooling. So what the max operator does is really it says, if the feature is detected anywhere in this filter, then keep a high number. But if this feature is not detected, so maybe the feature doesn't exist in the upper right hand quadrant, then the max of all those numbers is still itself quite small.
Parameters: filter size f and stride s. The output size of pooling will be the same as strided convolution output. Typically, f = 2, s = 2; f = 3, s = 2; Mostly, maxpooling doesn't use padding.
No parameters to learn in backprob.
Maxpooling is done independently on each channel of input.
Usually, doesn't use any padding.

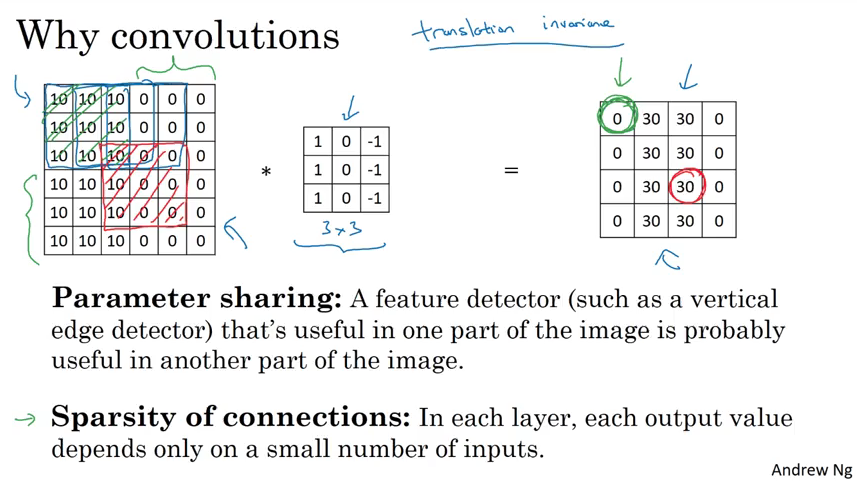
Why using convolutional neural networks?
- Advantage of CNN: Parameter sharing and sparsity of connections!
How to speed up convolution computation
Convert the convolution computation into matrix multiplication